| Situation | Beispiel | Folge |
Redundanz
Eine Eigenschaft enthält in vielen Datensätzen den selben Wert. |
In einer Dokument-Liste steht im Feld Pfad bei allen Datensätzen '/public/applications/abc/release/documents/'. |
Sollte sich der Pfad irgendwann ändern, müssen alle betroffenen Datensätze aktualisiert werden.
Im schlimmsten Fall steht kein Automatismus zur Verfügung, und die Bearbeitung erfolgt im Fließbandverfahren manuell: neben Tippfehlern besteht die Gefahr, den ein oder anderen Datensatz zu übersehen.
Selbst bei einer Automatisierung (UPDATE ... SET Pfad=... WHERE Pfad=...) werden manche Datensätze evtl. nicht erfasst; nämlich jene, die bereits manuell bearbeitet wurden und dadurch nicht mehr dem Muster entsprechen. |
Aggregation
Eine einzelne Eigenschaft ist nicht kompakt, sondern besteht ihrerseits aus einer Gruppe von Eigenschaften (technisch gesehen einem Unterobjekt). |
In einem Grundstück-Datensatz sind die Kontaktdaten von Makler, Eigentümer und Vorbesitzer enthalten. |
Es werden unverhältnismäßig viele Felder benötigt, die das Ganze unübersichtlich und schwer pflegbar machen. |
Dynamik
Objekte eines Typs sind nicht konform, d.h. die Anzahl der Felder unterscheidet sich, oder die Feldanzahl ist grundsätzlich dynamisch. |
In einem CD-Datensatz werden Felder für die einzelnen Track-Titel angelegt.
Oder:
In einem Adress-Datensatz werden zwei Felder für Telefonnummern angelegt. |
Wenn die Feldanzahl nicht genau definierbar ist, werden i.d.R. Reservefelder angelegt, deren Anzahl sich an der geschätzten zu erwartenden Wertemenge orientiert - meist ein Erfahrungswert. Erweist sich diese Anzahl irgendwann als zu niedrig, muss die Tabelle erweitert werden.
Abgesehen davon, dass diese Reservefelder häufig ungenutzt bleiben, werden Queries umständlicher, wenn z.B. die belegten Felder ermittelt oder gar sortiert werden sollen. |
1:1 (Auslagerung)
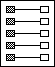
Diese einfache Art des Verweises dient der besseren - meist thematischen - Strukturierung von Datenblöcken.
Dadurch lassen sich Teilinformationen individueller verwalten, und der Umfang diesbezüglicher Skripte/Queries wird minimiert.
1:N (Hierarchie)
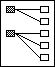
Die Hierarchie oder Baumstruktur ist eine erweiterte Form der Auslagerung, bei der mehrere Kindobjekte auf ein und dasselbe Elternobjekt verweisen können.
Je nachdem, welches Objekt den Primärschlüssel besitzt, kann alternativ auch gelten: mehrere Elternobjekte verweisen auf ein und dasselbe Kindobjekt (N:1).
N:N (Vernetzung)
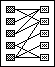
Bei der Vernetzung können zwischen den Elementen zweier Gruppen beliebige Verbindungen auftreten.
Diese Zuordnungen werden dann in einer separaten Tabelle verwaltet, in der jeweils die IDs der Partner vermerkt sind. Deshalb ist es nötig, dass hier
beide Objekttypen einen Primärschlüssel besitzen.
 admin
admin ID
ID Verweis
Verweis